Codificação de Caracteres, ASCII e Unicode
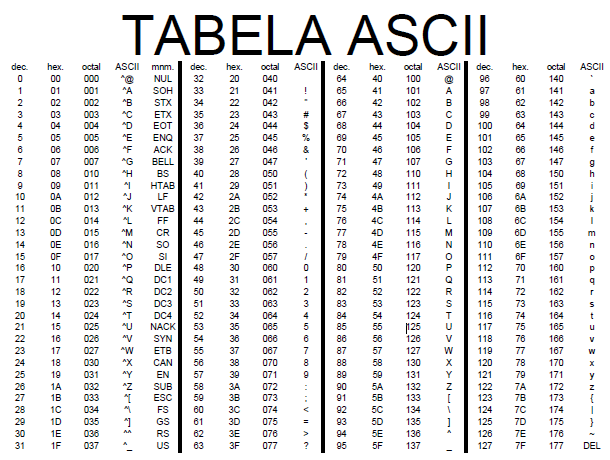
ASCII é uma sigla para “American Standard Code for Information Interchange” (Código Padrão Norte-americado para Intercâmbio de Informações). Esse código foi proposto por Robert W. Bemer, visando padronizar os códigos para caracteres alfa-numéricos (letras, sinais, números e acentos). Assim seria possível que computadores de diferentes fabricantes conseguissem entender os códigos.
O ASCII é, portanto, um código numérico que representa os caracteres, usando uma escala decimal de 0 a 127. Esses números decimais são então convertidos pelo computador para binários e ele processa o comando. Sendo assim, cada uma das letras que você digitar vai corresponder a um desses códigos.

Unicode é um padrão adotado mundialmente que possibilita com que todos os caracteres de todas as linguagens escritas utilizadas no planeta possam ser representados em computadores.
Unicode fornece um número único para cada caracterer, não importa a plataforma, não importa o programa e não importa a linguagem.
O padrão Unicode é capaz de representar não somente as letras utilizadas pelas linguagens mais “familiares” para nós ocidentais, como Inglês, Espanhol, Francês e o nosso Português, mas também letras e símbolos utilizados em qualquer outra linguagem: Russo, Japonês, Chinês, Hebreu, etc. Além disso, inclui símbolos de pontuação, símbolos técnicos e outros caracteres que podem ser utilizados em texto escrito.

Referências:


{kind=link}
{kind=link}
Boa imitação do Blogue do Vasco e do Nuno...
ResponderEliminar